Some while ago I was working with client who’s business was selling unique and highly detailed reports. Each report took months to compile and would cost their clients a fair amount of money.
When performing a routine check up of their site’s health in Google’s Search Console (aka Webmaster tools), I discovered that the client was ranking organically for the exact title of their latest report. Usually you’d expect this to be good news, but in this case we only had a rather generic page targeting the reports. Digging deeper into the Search Analytics report showed the they were actually ranking for the report itself, making it available to anyone freely.
Aside from the issue of the client giving it’s product away for free, it also highlights how certain assets can gain Organic ranking and drive actual traffic that remains unknown.
How is this happening?
Google’s crawlers can process documents similarly as it does with HTML pages. The most common formats you will find are PDF and Word Documents (Doc/Docx). If the document’s content is found relevant, you can find it ranking as an organic result alongside “regular” HTML pages.
A visitor entering these pages will go undetected, as no tracking is available for these (as JavaScript cannot be used). The only way to get a good estimate of their actual traffic is by looking at these documents in the Search Analytics report.
When examining this situation across several accounts, I discovered 5–15% of clicks landing on such pages. This is significant amount of traffic that flies under the radar.
But wait, why is this so bad?
Well the first and obvious reason is — you can’t measure it. Sort of the “tree falls in a forest” but with visitors on your site.
The second reason follows on the first — if you can’t measure it you can’t make it better (or if it’s already perfect, replicate it). I want to know if people read through my content or bounced right off. I want to know how they reached it and where they continued next. These measurements (among others) will help improve not only that specific piece, but also additional content that I will create and the overall experience of the users.
So if it’s ranking well on a topic I’m targeting, I have to know all the nitty gritty details.
So where do you start?
Step #1 — Identify all exposed assets
Start by mapping out which content on your domain Google has already been indexed.
The syntax for this is quite simple:
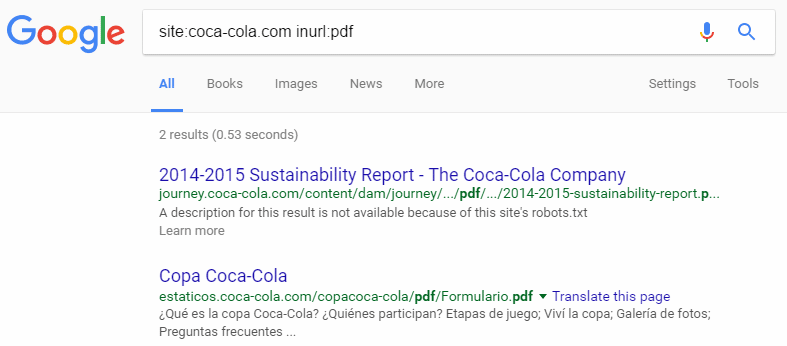
“site:mydomain.com inurl:pdf”
This should capture any PDF document within your domain and subdomains.
You can also tweak this to match only a specific subdomain, i.e. blog.example.com
Pro tip:
To prevent additional results being hidden by Google, be sure to click
“If you like, you can repeat the search with the omitted results included.”
Go over the results from Google to identify any unwanted results: internal documents, gated content that is available freely etc.
Step #2 — Check which assets receive traffic
Complete this by looking at the documents that actually rank and drive traffic.
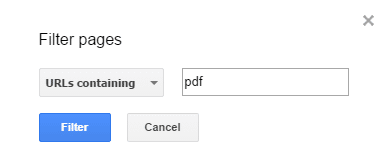
This is done in the Search Analytics report (in the Search Console), by filtering the Pages tab to show pages that include the string “PDF”.
Pro tip:
On the Pages tab, clicking on a specific page will limit the data to it, so when switching back to the Queries tab you can see the exact searches it ranks for.
Now you can tell which of these documents actually drive traffic and estimate the size of you “blind-spot”.
What can you do?
The answer here is simply — “it depends”.
Case 1: Ranking highly for a specific keyword
If it ain’t broke, don’t fix it.
Examine the document in case: does it use your up to date branding? is its content still relevant?
If some minor tweaks will do, then be just sure to update the document using the same link.
Case 2: Ranking badly for a specific keyword
At the end of the day, HTML pages rank better than documents. This is simply due the amount of indicators available on them. So for example, if a certain document competes for a keyword but can only hit second page, consider converting it into a proper HTML page. The content from the document should be adapted to the page’s layout and of course a proper redirect (301) from the document’s original path to its new location. Any boost to the content can also help, for example adding relevant media (images and videos) with proper tagging.
Case 3: Gated content left unlocked
In this case, the best course of action would be redirecting the document’s path to a new page with proper gating.
A “quick and dirty” solution will be to use a 301 redirect that will replace entirely the existing document’s path.
A better solution will be returning a 401 response while pointing to the registration page. This will indicate to bots that the content is indeed still there just not available without some identification.
In order for it to keep some of the existing Organic strength, I strongly recommend keeping a short excerpt available on the page.
Final thoughts
This phenomenon is one you expect to see only in websites that have been active for a long period of time. In most cases, I’ve found that the content was created several years ago and managed to rank undetected for an unknown period of time.
Now while most of ranking software in the market should identify such documents ranking for your domain, it still doesn’t solve the gap in measuring the actual engagement with them.
Using the above tactics can help both with bridging this data gap and exhausting existing content to drive more traffic.
Originally published on my blog on Medium.
